I'm taking a break from social media and focusing more on consuming written word, through books and web feeds via NewNewsWire. One of those feeds is Scour, an aggregation of my imported feeds automatically filtered based on interests -- especially useful for high-volume feeds like HN. This week my feed contained Adam Pritchard's article on limiting string length which contained this note:
Note that in Go, a Unicode code point is typically called a “rune”. (Go seems to have introduced the term for the sake of brevity. I certainly appreciate that, but I’m going to stick with universal terms here.)

When was the term "rune" introduced, and why? I thought I had seen it outside of Go, and did some digging.
As explained in Strings, bytes, runes, and characters in Go,
“Code point” is a bit of a mouthful, so Go introduces a shorter term for the concept: rune. The term appears in the libraries and source code, and means exactly the same as “code point”, with one interesting addition.
The Go programming language was created by a group including Rob Pike, Ken Thompson, and Russ Cox; all Bell Labs alumni who had collaborated on the Plan 9 operating system -- see Go at Google: Language Design in the Service of Software Engineering. Rob Pike is also the author of the Plan 9 editor Acme, from which I write this, which Russ Cox ported to UNIX (along with many Plan 9 utilities) in plan9port. Their experience on Plan 9 and Inferno meant many ideas from the Plan 9 C compiler and languages like Alef made it into Go -- the linker architecture, channels, the significance of capitalization, the focus on simplicity, the usage of "little languages," etc.
Plan 9 was also where UTF-8 was originally implemented, motivated by the difficulties with UTF-16 -- as Rob Pike writes in UTF-8 turned 20 years old:
UTF was awful. It had modulo-192 arithmetic, if I remember correctly, and was all but impossible to implement efficiently on old SPARCs with no divide hardware. Strings like "/*" could appear in the middle of a Cyrillic character, making your Russian text start a C comment. And more. It simply wasn't practical as an encoding: think what happens to that slash byte inside a Unix file name.
This email thread tells the story1:
Subject: UTF-8 history
From: "Rob 'Commander' Pike" <r (at) google.com>
Date: Wed, 30 Apr 2003 22:32:32 -0700 (Thu 06:32 BST)
To: mkuhn (at) acm.org, henry (at) spsystems.net
Cc: ken (at) entrisphere.com
Looking around at some UTF-8 background, I see the same incorrect
story being repeated over and over. The incorrect version is:
1. IBM designed UTF-8.
2. Plan 9 implemented it.
That's not true. UTF-8 was designed, in front of my eyes, on a
placemat in a New Jersey diner one night in September or so 1992.
What happened was this. We had used the original UTF from ISO 10646
to make Plan 9 support 16-bit characters, but we hated it. We were
close to shipping the system when, late one afternoon, I received a
call from some folks, I think at IBM - I remember them being in Austin
- who were in an X/Open committee meeting. They wanted Ken and me to
vet their FSS/UTF design. We understood why they were introducing a
new design, and Ken and I suddenly realized there was an opportunity
to use our experience to design a really good standard and get the
X/Open guys to push it out. We suggested this and the deal was, if we
could do it fast, OK. So we went to dinner, Ken figured out the
bit-packing, and when we came back to the lab after dinner we called
the X/Open guys and explained our scheme. We mailed them an outline
of our spec, and they replied saying that it was better than theirs (I
don't believe I ever actually saw their proposal; I know I don't
remember it) and how fast could we implement it? I think this was a
Wednesday night and we promised a complete running system by Monday,
which I think was when their big vote was.
So that night Ken wrote packing and unpacking code and I started
tearing into the C and graphics libraries. The next day all the code
was done and we started converting the text files on the system
itself. By Friday some time Plan 9 was running, and only running,
what would be called UTF-8. We called X/Open and the rest, as they
say, is slightly rewritten history.
Why didn't we just use their FSS/UTF? As I remember, it was because
in that first phone call I sang out a list of desiderata for any such
encoding, and FSS/UTF was lacking at least one - the ability to
synchronize a byte stream picked up mid-run, with less that one
character being consumed before synchronization. Becuase that was
lacking, we felt free - and were given freedom - to roll our own.
I think the "IBM designed it, Plan 9 implemented it" story originates
in RFC2279. At the time, we were so happy UTF-8 was catching on we
didn't say anything about the bungled history. Neither of us is at
the Labs any more, but I bet there's an e-mail thread in the archive
there that would support our story and I might be able to get someone
to dig it out.
So, full kudos to the X/Open and IBM folks for making the opportunity
happen and for pushing it forward, but Ken designed it with me
cheering him on, whatever the history books say.
-rob
That email chain includes the proposed FSS-UTF (File System Safe UTF) standard:
The proposed UCS transformation format encodes UCS values in the range
[0,0x7fffffff] using multibyte characters of lengths 1, 2, 3, 4, and 5
bytes. For all encodings of more than one byte, the initial byte
determines the number of bytes used and the high-order bit in each byte
is set.
An easy way to remember this transformation format is to note that the
number of high-order 1's in the first byte is the same as the number of
subsequent bytes in the multibyte character:
Bits Hex Min Hex Max Byte Sequence in Binary
1 7 00000000 0000007f 0zzzzzzz
2 13 00000080 0000207f 10zzzzzz 1yyyyyyy
3 19 00002080 0008207f 110zzzzz 1yyyyyyy 1xxxxxxx
4 25 00082080 0208207f 1110zzzz 1yyyyyyy 1xxxxxxx 1wwwwwww
5 31 02082080 7fffffff 11110zzz 1yyyyyyy 1xxxxxxx 1wwwwwww 1vvvvvvv
The bits included in the byte sequence is biased by the minimum value
so that if all the z's, y's, x's, w's, and v's are zero, the minimum
value is represented. In the byte sequences, the lowest-order encoded
bits are in the last byte; the high-order bits (the z's) are in the
first byte.
This transformation format uses the byte values in the entire range of
0x80 to 0xff, inclusive, as part of multibyte sequences. Given the
assumption that at most there are seven (7) useful bits per byte, this
transformation format is close to minimal in its number of bytes used.
And the UTF-8 proposal by Ken Thompson:
We define 7 byte types:
T0 0xxxxxxx 7 free bits
Tx 10xxxxxx 6 free bits
T1 110xxxxx 5 free bits
T2 1110xxxx 4 free bits
T3 11110xxx 3 free bits
T4 111110xx 2 free bits
T5 111111xx 2 free bits
Encoding is as follows.
>From hex Thru hex Sequence Bits
00000000 0000007f T0 7
00000080 000007FF T1 Tx 11
00000800 0000FFFF T2 Tx Tx 16
00010000 001FFFFF T3 Tx Tx Tx 21
00200000 03FFFFFF T4 Tx Tx Tx Tx 26
04000000 FFFFFFFF T5 Tx Tx Tx Tx Tx 32
See the File System Safe UCS Transformation Format by The Open Group, this version from 1995.
Importantly, it enables us to seek to the middle of a file or stream and read valid characters, or to handle a corrupted character:
All of the sequences synchronize on any byte that is not a Tx byte.
We can highlight the differences from FSS-UTF using RFC 3629, which uses the same tabular format:
The table below summarizes the format of these different octet types.
The letter x indicates bits available for encoding bits of the
character number.
Char. number range | UTF-8 octet sequence
(hexadecimal) | (binary)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Notably:
- The format is (as of RFC 3629, the first in the series which is not purely informational) limited to four bytes.
- Each subsequent byte has two leading bits,
10, which is required to distinguish them from a leading byte. - The first prefix is
110not10, also to enable distinguishing leading and following bytes.
These changes lead to a less dense representation where three bytes store exactly 16 bits and four bytes can store 21 bits.
In Rob Pike's paper on their implementation, Hello World, lies the first mention of Rune I could find:
On the semantic level, ANSI C allows, but does not tie down, the notion of a wide character and admits string and character constants of this type. We chose the wide character type to be unsigned short. In the libraries, the word Rune is defined by a typedef to be equivalent to unsigned short and is used to signify a Unicode character.
It seems likely that "rune" originated here, as its a kind of synonym for character (char). Later, ISO C99 Standard: 7.24 introduced "extended multibyte and wide character utilities" including the wchar_t type, see The wchar_t mess. ISO C99's locale functionality can also be surprising, see this HN post on how isspace() changes with locale.
Interestingly, in Plan 9 C they used an unsigned short (16-bits), but in Go the type is instead a signed int (32-bits) to support additional code points added since 1992. Remember, this encoding was meant to replace a two-byte encoding for exactly 16 bits of data (the Basic Multilingual Plane). In the original email, Ken notes:
The 4, 5, and 6 byte sequences are only there for political reasons. I would prefer to delete these.
And aligned with that, the paper mentions:
UTFmax = 3, /* maximum bytes per rune */
Three bytes could represent a maximum of 16 bits, while four bytes can represent a maximum of 21 bits. In Go, UTFMax = 4, and a rune is equivalent to a signed 32-bit integer. In plan9port, UTFmax = 4, and Rune is an unsigned integer -- a change Russ Cox made in late 2009. The Linux man page utf-8(7) notes that ISO 10464 defined UCS-2, a 16-bit code space, and UCS-4, a 31-bit code space; which justifies the signed 32-bit integer representation.
So, we've established Rune as existing at least as early as 1992 when UTF-8 was introduced, and was inherited by Go through its Plan 9 C lineage. Was it in use elsewhere in 1992? Searching the internet, I get a few hits:
-
FreeBSD rune functions, which it inherits from 4.4BSD; which states:
The setrunelocale() function and the other non-ANSI rune functions were inspired by Plan 9 from Bell Labs.
And further notes:
The 4.4BSD "rune" functions have been deprecated in favour of the ISO C99 extended multibyte and wide character facilities and should not be used in new applications.
Installing and Operating 4.4BSD UNIX from 1993 also include:
ANSI C multibyte and wide character support has been integrated. The rune functionality from the Bell Labs' Plan 9 system is provided as well.
-
Apple kernel docs for
rune_t, since Darwin derives from BSD this likely originates in BSD 4.4. -
newlib, a C standard library implementation including the rune functionality from BSD 4.4. -
Android's copy of
libutffrom Plan 9, ported by Russ Cox to UNIX as part ofplan9port. -
.NET's
System.Text.Runeinfluenced by Go; see the GitHub issue by Miguel de Icaza:As for why the name rune, the inspiration comes from Go
-
The MIT Jargon File includes:
runes pl.n.
- Anything that requires heavy wizardry or black art to parse: core dumps, JCL commands, APL, or code in a language you haven't a clue how to read. Compare casting the runes, Great Runes.
- Special display characters (for example, the high-half graphics on an IBM PC).
The Plan 9 rune functionality was incorporated into 4.4 BSD by Paul Borman, and became the ancestor to many of the uses of the term outside of the direct Plan 9 lineage. He would later join Google and contribute to the Go programming language 2. In machine/ansi.h, we can see that rune_t is defined as an int instead of as a unsigned short, with the following justification:
/*
* Runes (wchar_t) is declared to be an ``int'' instead of the more natural
* ``unsigned long'' or ``long''. Two things are happening here. It is not
* unsigned so that EOF (-1) can be naturally assigned to it and used. Also,
* it looks like 10646 will be a 31 bit standard. This means that if your
* ints cannot hold 32 bits, you will be in trouble. The reason an int was
* chosen over a long is that the is*() and to*() routines take ints (says
* ANSI C), but they use _RUNE_T_ instead of int. By changing it here, you
* lose a bit of ANSI conformance, but your programs will still work.
*
* Note that _WCHAR_T_ and _RUNE_T_ must be of the same type. When wchar_t
* and rune_t are typedef'd, _WCHAR_T_ will be undef'd, but _RUNE_T remains
* defined for ctype.h.
*/
The files e.g. rune.h, runetype.h all bear the copyright notice:
This code is derived from software contributed to Berkeley by Paul Borman at Krystal Technologies.

The only information I can find on Krystal Technologies is that it once owned krystal.com, and was later dragged into a dispute with the Krystal hamburger chain in 2000 (seven years after its mention in the rune files) which ended in a settlement.
FreeBSD still uses the rune types, e.g. in utf8.c, to provide wide character support for the UTF-8 locale.
The Unicode and ISO 10646 standards do not contain the term "rune" either. I reached out to Rob Pike on Bluesky to ask if "rune" did originate in Plan 9:
Actually Ken Thompson suggested it while the two of us were brainstorming for a type name that wasn't 'char'. He said triumphantly and I immediately agreed we had it.
Oh yes, and it was the name we needed in Plan 9 for UTF and ISO 10646, before Unicode and UTF-8 and decades before Go.
And later, Rob posted a confirmed origin date, thanking Geoff Collyer3 for searching through the Plan 9 dump:
The Plan 9 C source files /sys/src/libc/port/rune appeared in the daily backup on Dec 9, 1991, so the name was coined on the evening of the 8th.
So the term "rune" is over thirty years old, and has made its way from Plan 9 into 4.4 BSD and then several UNIX variants and C libaries, into Go and then into .NET, and through ports of libutf into Android.
Epilogue
Thanks to Adam Pritchard for noting some spelling errors on this post, which motivated me to write a small spelling utility for Acme, Spell, which wraps aspell's peculiar ispell-compatible output:
#!/usr/bin/env rc
file=`{basename $%}
name=`{dirname $%}'/+Spell'
id=`{9p read acme/index | 9 awk ' $6 == "'$name'" { print $1 }'}
if (~ $id '') id=new
id=`{9p read acme/$id/ctl | 9 awk '{print $1}'}
echo 'name '$name | 9p write acme/$id/ctl
printf , | 9p write acme/$id/addr
9p read acme/$winid/body \
| 9 sed 's/^/ /' \
| aspell pipe list --mode=url \
| 9 awk '
BEGIN { lines=1 }
/^&/ { gsub(/:/, "", $4); print "'$file':" lines ":" $4 "\t" $2 }
/^#/ { gsub(/:/, "", $3); print "'$file':" lines ":" $3 "\t" $2 }
/^$/ { lines++ }' \
| mc \
| 9p write acme/$id/data
echo clean | 9p write acme/$id/ctl
Button 2 clicking Spell in a window's tag opens a new +Spell window (or reuses an existing one) for the current directory, and writes misspelled words prefixed by its address. To navigate to a misspelled word, simply button 3 click on the address and make the correction.
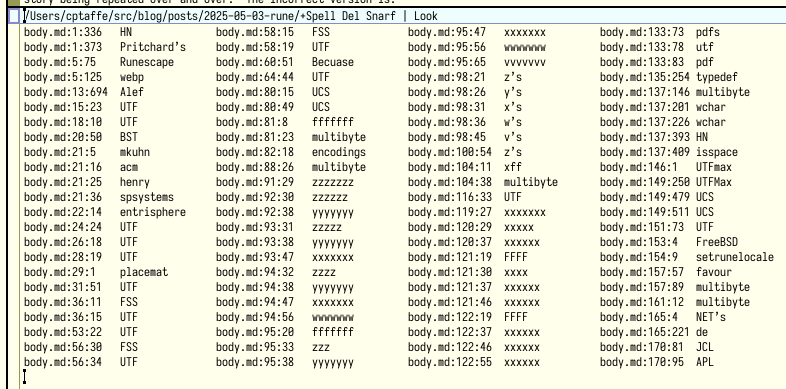
+Spell window in Acme-
In UTF-8 turned 20 years old, Rob Pike clarifies which diner:
↩︎The diner was the Corner Café in New Providence, New Jersey. We just called it Mom's, to honor the previous proprietor. I don't know if it's still the same, but we went there for dinner often, it being the closest place to the Murray Hill offices. Being a proper diner, it had paper placemats, and it was on one of those placemats that Ken sketched out the bit-packing for UTF-8. It was so easy once we saw it that there was no reason to keep the placemat for notes, and we left it behind. Or maybe we did bring it back to the lab; I'm not sure. But it's gone now.
-
Among his contributions is a
getoptstyle options pacakge as an alternative toflag. ↩︎ -
Geoff Collyer was a member of the technical staff at Bell Labs. He recently spoke about Plan 9 on 64-bit RISC-V. ↩︎