I use kubeadm for my home k8s cluster that I run my blog on. Yesterday, I refactored my blog server to push static resources to Google Cloud Storage and then pull those resources down in an init container, instead of packaging them in the container image. Originally, I planned to redirect to a signed GCS URL from my server application and have GCS handle serving static resources to the browser, but I ran into issues with page load time even with Cache-Control set to 48 hours. Eventually, I'd like to use a k8s storage class and push resources to NFS or similar served by a redundant local deployment.
The previous flow:
The updated flow:
I added the following init contianer to my deployment to pull resources into a new emptyDir volume:
...
apiVersion: apps/v1
kind: Deployment
...
spec:
...
template:
...
spec:
containers:
- ...
volumeMounts:
- name: resources
readOnly: true
mountPath: /usr/src/blog/resources
initContainers:
- name: init
image: gcr.io/google.com/cloudsdktool/google-cloud-cli:alpine
command: ["/bin/sh"]
args: ["-c", "gcloud auth activate-service-account --key-file=/var/gcp-creds/creds.json; gsutil -m rsync -r gs://connor.zip/resources /var/resources"]
volumeMounts:
- name: gcp-creds
readOnly: true
mountPath: /var/gcp-creds
- name: resources
mountPath: /var/resources
volumes:
- name: gcp-creds
secret:
secretName: gcp-creds
- name: resources
emptyDir: {}
I used the google-cloud-cli container for access to the gsutil command. The gsutil command doesn't look at the GOOGLE_APPLICATION_CREDENTIALS environment variable like the SDK client would, so we need to instead call
; gcloud auth activate-service-account --key-file=/var/gcp-creds/creds.json
Once the init container scheduled, it wouldn't finish rsync-ing files and instead showed:
; kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-67f956dd6-26q85 0/1 Init:0/1 0 7s
The logs for the pod showed a connectivity issue:
; kubectl logs pods/blog-67f956dd6-26q85 -c init
INFO 0223 06:29:43.857160 retry_util.py] Retrying request, attempt #2...
So, why can't gsutil complete the request? Let's check the pod's connectivity:
; kubectl exec -it blog-b85849cd-8j4mf -c init -- /bin/sh
/ # ping google.com
ping: bad address 'google.com'
/ # curl google.com
curl: (6) Could not resolve host: google.com
Now that we've identified the issue as DNS, we can follow the instructions at Debugging DNS Resolution. The resolution flow in my network is shown below:
DNS resolution within a pod is managed by k8s, which manages the /etc/resolv.conf file. Our pod has one like:
search default.svc.cluster.local svc.cluster.local cluster.local home.arpa
nameserver 10.96.0.10
options ndots:5
We should ensure our kube-dns service has the correct cluster IP:
; kubectl get svc/kube-dns -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.3.0.10 <none> 53/UDP,53/TCP,9153/TCP 466d
There is a mismatch! For me, the reason is that the kube-dns IP is mismatched is that the worker's config wasn't reflecting the updated IP I chose for kube-dns. Previously, I had manually updated the /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf file on the node. When I updated the node, the ConfigMap stored in k8s overwrote this file. The section of k8s docs on Updating the KubeletConfiguration instructs us to edit:
; kubectl edit cm -n kube-system kubelet-config
In my cluster, the config contained:
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
which is outdated, it needed to be updated to:
clusterDNS:
- 10.3.0.10
clusterDomain: k8s.home.arpa
This is because my kube-dns service exists within the 10.3.x.x IP range, and because I want k8s DNS addresses to be placed under my home networks home.arpa DNS zone. The pfSense firewall is configured to delegate DNS for the 10.3.x.x and 10.2.x.x service and pod networks, as well as k8s.home.arpa to Kubernetes so that I can easily reach k8s resources from the rest of the network. For instance, this blog is accessible on my local network via http://blog.default.svc.k8s.home.arpa/.
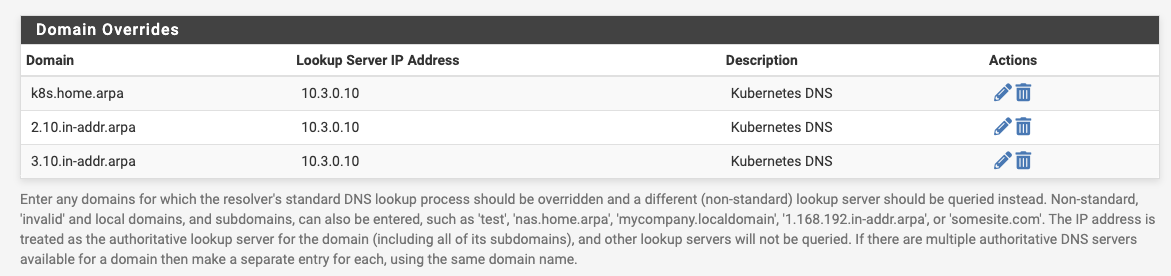
Once updated, your nodes need to be updated:
; sudo kubeadm upgrade node phase kubelet-config
[upgrade] Reading configuration from the cluster...
[upgrade] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[upgrade] The configuration for this node was successfully updated!
[upgrade] Now you should go ahead and upgrade the kubelet package using your package manager.
; sudo systemctl restart kubelet.service
This will update the /etc/resolv.conf on pods created by the kubelet to reflect our new dns and domain configuration. We may need to roll pods so they reflect this.
The CoreDNS config can be edited with:
; kubectl -n kube-system edit configmap coredns
which contains:
.:53 {
log
errors
health {
lameduck 5s
}
ready
kubernetes k8s.home.arpa in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
The log line was added to help with debugging. The k8s.home.arpa mentions on the kubernetes line is meant to coincide with our clusterDomain configuration in kubelet, and the /etc/resolv.conf follows system configuration when forwarding. We can get this configuration by running a dnsutils pod:
apiVersion: v1
kind: Pod
metadata:
name: dnsutils
namespace: default
spec:
containers:
- name: dnsutils
image: registry.k8s.io/e2e-test-images/jessie-dnsutils:1.3
command:
- sleep
- "infinity"
imagePullPolicy: IfNotPresent
dnsPolicy: Default
restartPolicy: Always
This pod will receive the same /etc/resolv.conf that CoreDNS will since it has dnsPolicy: Default. On my system, the kubelet is configured to pull /etc/resolv.conf from /run/systemd/resolve/resolv.conf, which contains:
...
nameserver 10.0.0.1
nameserver 2600:1700:f08:111f:20c:29ff:fe6f:1149
nameserver 10.0.0.1
# Too many DNS servers configured, the following entries may be ignored.
nameserver 2600:1700:f08:111f:20c:29ff:fe6f:1149
search home.arpa
In the logs for CoreDNS, I noticed errors around resolution of GCS DNS:
; kubectl logs --namespace=kube-system -l k8s-app=kube-dns -f
...
[INFO] 10.2.110.43:50804 - 1443 "A IN storage.googleapis.com.home.arpa. udp 50 false 512" SERVFAIL qr,aa,rd,ra 50 0.000196806s
The search home.arpa line is informing CoreDNS to test DNS addresses within .home.arpa as well as globally, but lookups are failing within the .home.arpa zone. It turns out that pfSense’s unbound can get overloaded if set in recursive mode. Since the /etc/resolv.conf search line contains home.arpa, every domain gets tested with that suffix e.g. google.com.home.arpa.
Under Services, DNS Resolver in pfSense, I could see “System Domain Local Zone Type” configured as Transparent, which attempts to ask upstream if x.home.arpa wasn’t present. Swapping this to Static avoids this lookup and return an NXDOMAIN if no overrides are present, since pfSense should be the owner of .home.arpa. I also toggled on forwarding mode so that it hits the upstream DNS server for zones it doesn’t manage instead of being a recursive resolver itself.
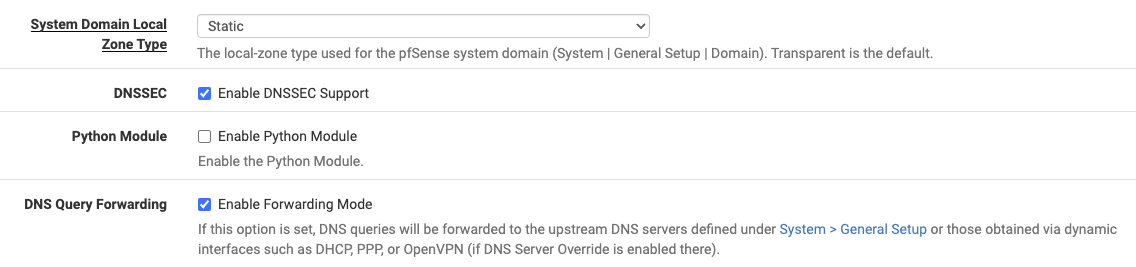
These changes solved my issue and the init container was able to pull resources from GCR. I later realized that setting the "System Domain Local Zone Type" to Static caused the Domain Overrides for k8s.home.arpa to fail, so I switched it back to Transparent. So far, DNS within Kubernetes is working properly:
; kubectl exec -i -t dnsutils -- nslookup google.com
Server: 10.3.0.10
Address: 10.3.0.10#53
Non-authoritative answer:
Name: google.com
Address: 142.250.113.101
Name: google.com
Address: 142.250.113.100
Name: google.com
Address: 142.250.113.138
Name: google.com
Address: 142.250.113.102
Name: google.com
Address: 142.250.113.113
Name: google.com
Address: 142.250.113.139