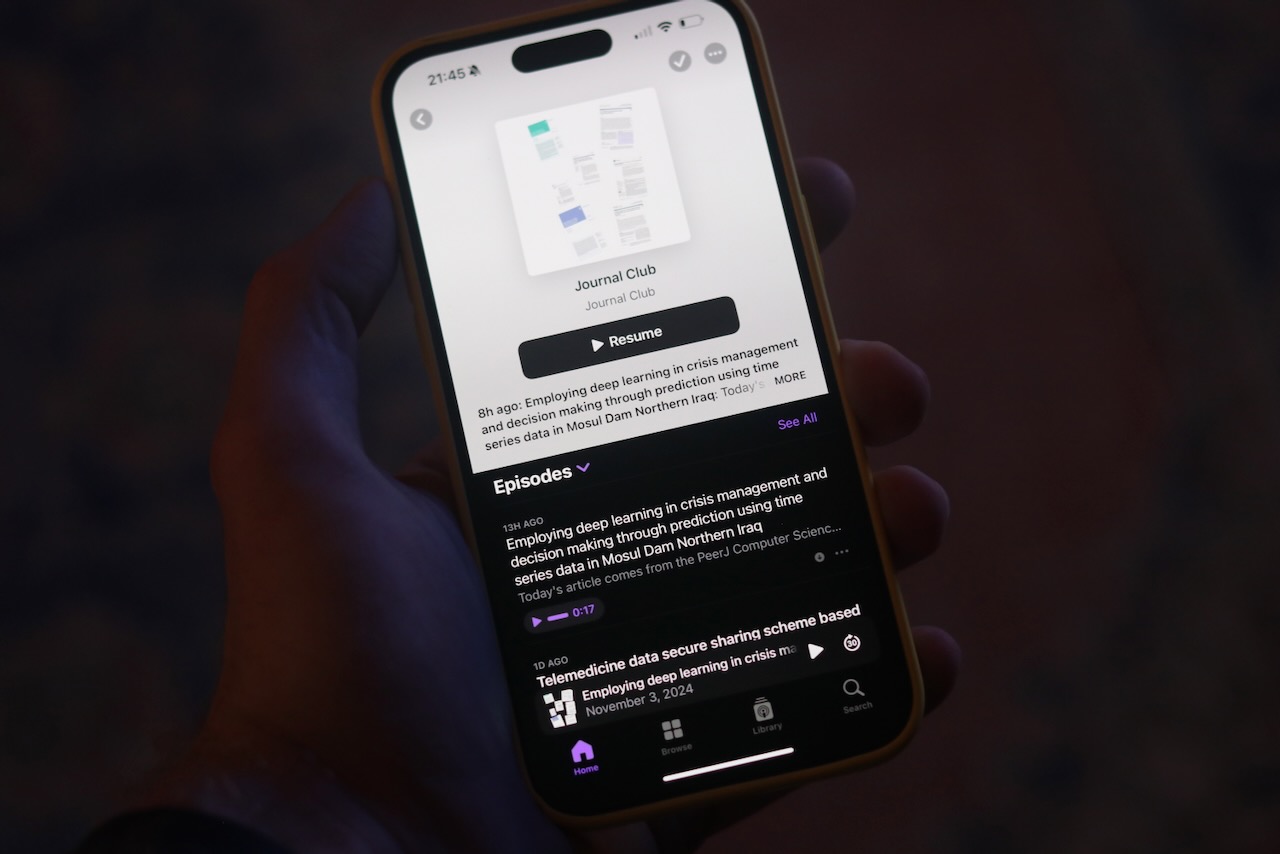
Recently, I subscribed to a new newsletter and podcast called Journal Club, a daily email in which Malcolm Diggs walking through a recently published paper related to the field of computer science -- often involving machine learning. It contains a transcript and links to an audio recording and the paper. Unfortunately, this isn't how I like to consume podcasts. Instead, I use the Apple Podcasts app on my iPhone.
Is there a way to go from a series of emails in my iCloud account to an iTunes podcast?
I use a custom domain with iCloud mail to receive mail at connor.zip addresses. Since I don't control my mail server, I can't use existing filter languages like Sieve to move or otherwise process emails.
MailRules
Instead, I wrote a simple mail filtering utility which connects via IMAP and listens for new messages to process. mailrules takes simple text rules such as:
if to ~ "^marketing[\\+\\.]"
then move "Marketing";
This rule allows me to give out the address marketing+llbean@connor.zip, and when those emails arrive from any From address, they'll be delivered to the Marketing folder. Usually bogus email addresses would be returned to sender by iCloud, but with the catch all setting enabled they'll be delivered to my main address.
- When
mailrulesstarts, it applies its rules to all emails the inbox. - Then, it waits for additional events such as incoming emails and applies any rules to that email.
I use a goyacc generated parser to implement the rule language, which uses as input tokens from the lexer. The lexer is a modified version of Eli Bendersky's A Faster Lexer in Go1. The parser builds a list of rules from the input rules file, and matches those rules in order to each email based on the metadata fetched from the email server.
For instance, the above rule would become the tokens:
IF IDENTIFIER TILDE QUOTE THEN MOVE QUOTE SEMICOLON
Let's walk through the relevant yacc rules:
- We start at the
rulesrule, defined as either a single rule or a series of semicolon-delimited rules. Here we stripSEMICOLONoff the end andrulemust beIF IDENTIFIER TILDE QUOTE THEN MOVE QUOTE.rules: rule SEMICOLON { $$ = append($$, $1) } ... - One of the options for a
ruleis anif ... thenpredicate followed by amoveaction. Here we break our tokens apart into aIDENTIFIER TILDE QUOTEandMOVE QUOTEto fill in the blanks.rule: IF condition THEN move { $4.Predicate = $2 $$ = $4 } ... - Focusing on the latter part of the
if ... then, themoveis a simple keyword followed by astring. Notice its first argument, the predicate, is empty; it's assigned within theif ... thenrule once theconditionis resolved. WithMOVEcovered,stringmust beQUOTE.move: MOVE string { $$ = rules.NewMoveRule(nil, $2) } - Within the
if ... then, theconditioncan be a simplecomparison, or it can containand,or,not, etc. We're still handlingIDENTIFIER TILDE QUOTEat this point.condition: comparison { $$ = $1 } ... - The
comparisonwe use here is the~regular expression match. WithIDENTIFIER TILDEcovered,stringmust beQUOTE.comparison: IDENTIFIER TILDE string { rexp, err := regexp.Compile($3) if err != nil { yylex.Error(fmt.Sprintf("malformed regex '%s' in predicate: %v", $3, err)) return -1 } $$, err = rules.NewFieldPredicate($1, rexp) if err != nil { yylex.Error(err.Error()) return -1 } } ... - And as we expect,
stringis aQUOTEatom where we've handled normalizing escaped quotes:string: QUOTE { $$ = strings.ReplaceAll(strings.ReplaceAll($1[1:len($1)-1], "\\\"", "\""), "\\\\", "\\") }
Which results in [MoveRule(FieldPredicate("to", /^marketing[\+\.]/), "Marketing")].
I then use the go-imap package to interact with the mail server. First we fetch metadata from the input server, the following is condensed:
- Connect using TLS to our mail server
- Login using our application credentials
- Select the
INBOXas our active mailbox - Use an infinite range to select all emails
c, _ := client.DialTLS("imap.mail.me.com:993", nil)
c.Login("username", "password")
mbox, _ := c.Select("INBOX", false)
// within processMailbox
seqset := new(imap.SeqSet)
seqset.AddRange(1, 0)
messages := make(chan *imap.Message, 10)
done := make(chan error, 1)
go func() {
done <- c.UidFetch(seqset, []imap.FetchItem{imap.FetchUid, imap.FetchEnvelope}, messages)
}()
We use UIDs instead of sequence numbers because the sequence number of a message will change if a message with a lower sequence number is moved out of the inbox, which can lead to strange behavior. The envelope contains just enough metadata to apply our rules, without pulling the entire body and attachments.
Then, we apply rules to each of the emails.
for msg := range messages {
for _, rule := range rules {
rule.Message(msg)
}
}
The rules are then applied to all emails they matched in the order of the rules file:
for _, rule := range rules {
err := rule.Action(c)
if err != nil {
log.Println("Apply rule:", err)
}
}
After the first pass, we wait for additional emails regarding our mailbox and at that point re-process:
for {
processMailbox(c, mbox, rules)
log.Println("Listening...")
// Create a channel to receive mailbox updates
updates := make(chan client.Update)
c.Updates = updates
// Start idling
stop := make(chan struct{})
done := make(chan error, 1)
go func() {
done <- c.Idle(stop, nil)
}()
// Listen for updates
for {
select {
case update := <-updates:
switch update := update.(type) {
case *client.MailboxUpdate:
if update.Mailbox.Name != "INBOX" {
break
}
log.Println("Saw change to Inbox")
// stop idling
close(stop)
close(updates)
c.Updates = nil
}
case err := <-done:
if err != nil {
log.Fatal(err)
}
goto Process
}
}
Process:
}
The rule keeps track of which messages matched and resets its internal state within Action. For instance, the Message match function for the move rule looks like:
func (r MoveRule) Message(msg *imap.Message) {
if r.Predicate.MatchMessage(msg) {
log.Printf("Moving '%s' to '%s'", msg.Envelope.Subject, r.Mailbox)
r.messages.AddNum(msg.Uid)
}
}
Here r.messages is an imap.SeqSet, which is used to represent a set of message UIDs. Also note that the predicate is pluggable and is swapped in by the parser matching logic based on whether the predicate is a simple regex or equivalence match or a more complex boolean logic statement.
Stream
To keep mailrules a generic IMAP email processing tool, I added a new stream command, which can be plugged into any number of backends. The rule looks like this:
if from ~ "^members@journalclub.io$"
then stream rfc822 "curl --silent --show-error --fail-with-body --header \"Content-Type: message/rfc822\" --header \"Accept: application/json\" --data-binary @- http://email2rss/journalclub/email";
When the from address matches our regular expression, this rule sends the entire RFC 822 formatted email message into the input of the command provided. The command can be anything, in this case we use curl to send the body of the email to a sibling service running on the same Kubernetes cluster, email2rss.
To fetch the full representation of the email, StreamRule's Action function:
- Initiates a Fetch using the UID set constructed in its
Messagematching logic, in which it asks forUID,RFC822.HEADER, andRFC822.TEXT. - Finds the header and text portions of the response for a given message and concatenates them together.
- Executes the command with the stdin set to the message.
Since this rule asks for the rfc822 representation of a message instead of html, we don't attempt to parse the body of the message.
Podcasts
Apple Podcasts supports ingesting RSS feeds as long as they meet its requirements, which mostly involves the use of the itunes namespace and the recently standardized podcast namespace. See also Apple's required tags page and their sample feed.
Here's an example of what we need to produce:
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0"
xmlns:atom="http://www.w3.org/2005/Atom"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd"
xmlns:podcast="https://podcastindex.org/namespace/1.0" >
<channel>
<title>Journal Club</title>
<link>https://journalclub.io/</link>
<atom:link href="{REDACTED}" rel="self" type="application/rss+xml" />
<language>en-us</language>
<copyright>© 2024 JournalClub.io</copyright>
<itunes:author>Journal Club</itunes:author>
<description> Journal Club is a premium daily newsletter and podcast authored and hosted by Malcolm Diggs. Each episode is lovingly crafted by hand, and delivered to your inbox every morning in text and audio form.</description>
<itunes:image href="https://www.journalclub.io/cdn-cgi/image/width=1000/images/journals/journal-splash.png"/>
<itunes:category text="Science" />
<itunes:explicit>false</itunes:explicit>
<item>
<title>Employing deep learning in crisis management and decision making through prediction using time series data in Mosul Dam Northern Iraq</title>
<description>
<![CDATA[
<p>Today's article comes from the PeerJ Computer Science journal. The authors are Khafaji et al., from the University of Sfax, in Tunisia. In this paper they attempt to develop machine learning models that can predict the water-level fluctuations within a dam in Iraq. If they succeed, it will help the dam operators prevent a catastrophic collapse. Let's see how well they did.</p>]]>
</description>
<guid isPermaLink="false">1b1dd75f-e37e-4c55-b759-dea3b1dbba3a</guid>
<pubDate>Sun, 03 Nov 2024 13:55:35 UTC</pubDate>
<enclosure url="{REDACTED}" length="12926609" type="audio/mpeg" />
<itunes:image href="https://embed.filekitcdn.com/e/3Uk7tL4uX5yjQZM3sj7FA5/sSM8ecFNXywfm7M3qy1tWu" />
<itunes:explicit>false</itunes:explicit>
</item>
</channel>
</rss>
Podcasts are RSS 2.0 feeds, in 2023 Apple deprecated the use of Atom feeds.
| Object | Fields | Description |
|---|---|---|
<channel> |
<title> |
The title of the feed, we use the name of the newsfeed. |
<channel> |
<link> |
A link to the source of the information in the feed. Since this feed is based on an email newsletter and not a website, we use the homepage of the feed. |
<channel> |
<atom:link> |
A self-link in the atom namespace, back-porting this feature from the Atom feed specification to RSS 2.0. We place the URL of the feed file itself here. |
<channel> |
<language> |
The language of the content, in the same format of the Accept-Language HTTP header. |
<channel> |
<copyright> |
Who owns the rights to the content in this file, we use the copyright statement from the homepage. |
<channel> |
<itunes:author> |
This is the first of the itunes namespaced fields, the author of the content. |
<channel> |
<description> |
A description of the content, we use the one available on the website. |
<channel> |
<itunes:image> |
The image to use as cover art. |
<channel> |
<itunes:category> |
The category of the podcast, this can also contain a subcategory. |
<channel> |
<itunes:explicit> |
Whether or not this podcast contains explicit content. |
<item> |
<title> |
The title of a podcast episode, extracted from the Subject line of the email. |
<item> |
<description> |
A description of the podcast episode, taken from the first paragraph of the body of the email. This field can contain HTML tags such as paragraphs and links by using a CDATA block. |
<item> |
<guid> |
A globally unique id, we use X-Apple-UUID so we must set isPermaLink to false since it's not a URL to the content. |
<item> |
<pubDate> |
The date the podcast episode was published, we use the Date field from the email. This won't work in the case of back-dated episodes, for instance JournalClub has a mechanism to resend old episodes and those emails would have a renewed send date. |
<item> |
<enclosure> |
The audio of the podcast episode, a URL along with its MIME type and file size. |
<item> |
<itunes:image> |
The image to use for a specific podcast episode. We use the paper image, but it's so small Apple's podcast app ignores it. |
<item> |
<itunes:explicit> |
Whether this particular episode is explicit. |
We can use the W3C Feed Validation Service and the Podbase Podcast Validator for podcast-specific validation.
Email2RSS
At this point, mailrules has shelled out to curl which has sent the body of our Journal Club email to a sibling email2rss service, in the same Kubernetes cluster which mailrules is deployed within. This service has two relevant endpoints:
GET /{feed}/feed.xmlwhich fetches the generated Podcast RSS.POST /{feed}/emailwhich accepts an RFC 822 formatted email and updates the Podcast RSS.
POST /{feed}/email
The POST endpoint needs to first parse the input email to find the HTML representation we'll be pulling relevant information from. To do that, we first need to parse the RFC 822 message body using Go's net/mail package using mail.ReadMessage(req.Body). Then, we extract the msg.Header.Date() which (RFC 3339 formatted) becomes the key for our state in cloud storage.
MIME2
To find the HTML, we use the MessageMIME method:
// MessageMIME finds and parses a portion of the message based on the MIME type
func MessageMIME(message *mail.Message, contentType string) (io.Reader, error) {
mediaType, params, err := mime.ParseMediaType(message.Header.Get("Content-Type"))
if err != nil {
return nil, fmt.Errorf("parse message content type: %w", err)
}
if !strings.HasPrefix(mediaType, "multipart/") {
return nil, fmt.Errorf("expected multipart message but found %s", mediaType)
}
reader := multipart.NewReader(message.Body, params["boundary"])
if reader == nil {
return nil, fmt.Errorf("could not construct multipart reader for message")
}
for {
part, err := reader.NextPart()
if err != nil {
return nil, fmt.Errorf("could not find %s part of message: %w", contentType, err)
}
mediaType, _, err := mime.ParseMediaType(part.Header.Get("Content-Type"))
if err != nil {
return nil, fmt.Errorf("parse multipart message part content type: %w", err)
}
if mediaType == contentType {
enc := strings.ToLower(part.Header.Get("Content-Transfer-Encoding"))
switch enc {
case "base64":
return base64.NewDecoder(base64.StdEncoding, part), nil
case "quoted-printable":
return quotedprintable.NewReader(part), nil
default:
return part, nil
}
}
}
}
The method parses the Content-Type header of the message to determine if it is multipart/, if so we need to determine the boundary string used to split each portion and iterate through each of the multiple parts using a multipart.Reader. As we iterate over each part, we again parse the Content-Type looking for our target text/html. Each of these message parts could be another multipart message (in which case we could recurse) or even an entire email (message/rfc822); but for our purposes we only expect a single level in the tree. Once we've found the appropriate portion, we check Content-Transfer-Encoding; in our case the email is quoted-printable3 encoded, which looks like:
<h3 style=3D"font-weight:bold;font-style:normal;font-size:1em;margin:0;font=
-size:1.17em;margin:1em 0;font-family:Charter, Georgia, Times New Roman, se=
rif;font-size:28px;color:#12363f;font-weight:400;letter-spacing:0;line-heig=
ht:1.5;text-transform:none;margin-top:0;margin-bottom:0" class=3D"">Employi=
ng deep learning in crisis management and decision making through predictio=
n using time series data in Mosul Dam Northern Iraq</h3>
Notice the trailing = for soft line-breaks and =3D to encode literal equal signs.
I may rewrite this in the future to leverage a more general library like go-message.
Parsing the HTML
Next, we extract information form the message using regular expressions4:
| Expression | Description |
|---|---|
"(https?://[^ ]+\.mp3)" |
The audio recording link included in each email, which becomes the <enclosure> url field. |
<img src="(https?://[^ ]*)" |
An image of the first page of the paper we can use as the podcast episode <itunes:image>. Unfortunately this is too low-resolution to be used by the Podcast app. |
Hi[ ]+Connor, (.*)</p> |
The <description> of each episode, which begins with a salutation specific to each subscriber. |
<a [^>]*href="(https?://(\w+\.)?doi.org[^"]*)"[^>]*> |
The link to the paper, using the DOI. This becomes part of the <description>. |
Apple requires the <enclosure> length field contain the number of bytes within the file, so we send a HEAD request to the audio URL and record the Content-Length to populate this field.
We also extract some information from headers:
| Header | Description |
|---|---|
Subject |
Populates <title>, but needs UTF-8 characters decoded according to RFC 2047 using mime.WordDecoder's DecodeHeader |
Date |
Used for the file name in cloud storage. |
X-Apple-UUID |
Used for the <guid> tag. |
Once we've extracted this information, we format our state into a JSON blob and write it to storage:
{
"uuid": "1b1dd75f-e37e-4c55-b759-dea3b1dbba3a",
"subject": "Employing deep learning in crisis management and decision making through prediction using time series data in Mosul Dam Northern Iraq",
"description": "Today's article comes from the PeerJ Computer Science journal. The authors are Khafaji et al., from the University of Sfax, in Tunisia. In this paper they attempt to develop machine learning models that can predict the water-level fluctuations within a dam in Iraq. If they succeed, it will help the dam operators prevent a catastrophic collapse. Let's see how well they did.",
"date": "2024-11-03T13:55:35Z",
"imageURL": "https://embed.filekitcdn.com/e/3Uk7tL4uX5yjQZM3sj7FA5/sSM8ecFNXywfm7M3qy1tWu",
"audioURL": "{REDACTED}",
"audioSize": 12926609,
"paperURL": "http://dx.doi.org/10.7717/peerj-cs.2416"
}
Then, all state files are read in from cloud storage and passed through a template to generate the new Podcast RSS feed:
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0"
xmlns:atom="http://www.w3.org/2005/Atom"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd"
xmlns:podcast="https://podcastindex.org/namespace/1.0" >
<channel>
<title>Journal Club</title>
<link>https://journalclub.io/</link>
<atom:link href="{REDACTED}" rel="self" type="application/rss+xml" />
<language>en-us</language>
<copyright>© 2024 JournalClub.io</copyright>
<itunes:author>Journal Club</itunes:author>
<description> Journal Club is a premium daily newsletter and podcast authored and hosted by Malcolm Diggs. Each episode is lovingly crafted by hand, and delivered to your inbox every morning in text and audio form.</description>
<itunes:image href="https://www.journalclub.io/cdn-cgi/image/width=1000/images/journals/journal-splash.png"/>
<itunes:category text="Science" />
<itunes:explicit>false</itunes:explicit>
{{- range . }}
<item>
<title>{{.Subject}}</title>
<description>
<![CDATA[
<p>{{- .Description -}}</p>
{{- if .PaperURL -}}
<p>Want the paper? This <a href="{{.PaperURL}}">link</a> will take you to the original DOI for the paper (on the publisher's site). You'll be able to grab the PDF from them directly.</p>
{{- end -}}
]]>
</description>
<guid isPermaLink="false">{{.UUID}}</guid>
<pubDate>{{ rfc2822 .Date }}</pubDate>
<enclosure
url="{{.AudioURL}}"
length="{{.AudioSize}}"
type="audio/mpeg"
/>
<itunes:image href="{{.ImageURL}}" />
<itunes:explicit>false</itunes:explicit>
</item>
{{- end }}
</channel>
</rss>
And the final output is cached in cloud storage.
GET /{feed}/feed.xml
Using the portable blob package, we can avoid coupling ourselves to a specific cloud storage backend, and even write tests using a mem or file backend. Then, we use http.ServeContent to handle the finicky logic around Last-Mofied/If-Modified-Since and friends. Here's the implementation of GetFeed:
func (s *Server) GetFeed(w http.ResponseWriter, req *http.Request) {
ctx := req.Context()
key := fmt.Sprintf("%s/feed.xml", req.PathValue("feed"))
attrs, err := s.bucket.Attributes(ctx, key)
if err != nil {
http.Error(w, "Could not fetch feed attributes", http.StatusInternalServerError)
log.Printf("fetch object attributes: %v", err)
return
}
blobReader, err := s.bucket.NewReader(ctx, key, nil)
if err != nil {
http.Error(w, "Could not fetch feed", http.StatusInternalServerError)
log.Printf("construct object reader: %v", err)
return
}
defer blobReader.Close()
w.Header().Add("Content-Type", "application/xml+rss;charset=UTF-8")
w.Header().Add("Content-Disposition", "inline")
w.Header().Add("Cache-Control", "no-cache")
w.Header().Add("ETag", attrs.ETag)
http.ServeContent(w, req, "", blobReader.ModTime(), blobReader)
}
We can finally put the entire flow together:
Using
Once the email2rss's GET /{feed}/feed.xml endpoint has been published to the internet, and mailrules is sending emails to the service to populate the RSS feed; we can finally open the Podcasts app and see what we've accomplished.
- On mobile, navigate in the Apple Podcasts app on iPhone to Library > ..., then Follow a Show by URI..., then paste the full URL of our
feed.xmlendpoint. - On desktop, navigate to File > Follow a Show by URI... (or command+shift+N).

-
See also Lexical Scanning in Go by Rob Pike, which I've used as the basis for several previous projects involving lexers. ↩︎
-
MIME was introduced as an email standard in 1992, see a brief history in The MIME guys: How two Internet gurus changed e-mail forever. Its use in the Web through
Content-Typeand laterAccepthas not been with hiccups necessitating that browsers sniff content and even a MIME Sniffing standard. ↩︎ -
Email predates the Internet, and is always ASCII encoded. ASCII was introduced as a 7-bit standard for telegraphs in the 60s, so to represent 8-bit UTF-8 characters, we need a way to encode the 8-bit characters into 7-bit ASCII. The
quoted-printablescheme (RFC 2045 §6.7) does this by using an=sign followed by two hex digits. In the case of a literal equals sign in the original text, it must be encoded=3D,3Dbeing the hex for the ASCII code for=. Quoted printable also requires that lines be a maximum of 76 characters long, if the original text is a longer a soft line break can be inserted which results in a=before the\r\nsequence. The only mention of line length in RFC 822 is when referencing long headers:"Long" is commonly interpreted to mean greater than 65 or 72 characters. The former length serves as a limit, when the message is to be viewed on most simple terminals which use simple display software; however, the limit is not imposed by this standard.
Long ago, email was delivered on UNIX machines using UUCP (UNIX-to-UNIX Copy), to user-specific mailboxes and viewed with a command such as
mail. In fact email addresses looked much different before DNS, for instance a UUCP bang path representing the full route to the sender or recipient. As an example, Brian Ried's essay on Interpress was sent from the addressdecwrl!glacier!reid. ↩︎ -
These were ported from my first attempt at a solution, which involved integrating the HTML parser into
mailrulesand generatingitem.xmlintermediate files which were globbed into a finalfeed.xmlall via shell script. Thehtmlcommand input is still an option for thestreamrule in place ofrfc822. I then usedgsutil rsyncto copy files from themailrulespod shell script workspace to cloud storage, and a simple static server container using BusyBox'shttpdand the samegsutil rsyncin an init container and in a loop as a sidecar using a shared empty volume. ↩︎